
OEE Monitoring for Small Manufacturers: Making the Number Mean Something
OEE monitoring is sold as a dial that tells you how well your machines are running. The catch nobody mentions: a number your floor doesn't trust is worse than no number, because people make decisions on it. Here's what OEE actually measures, why most standalone OEE platforms become another ignored dashboard, and how to capture it inside the work your team already does.
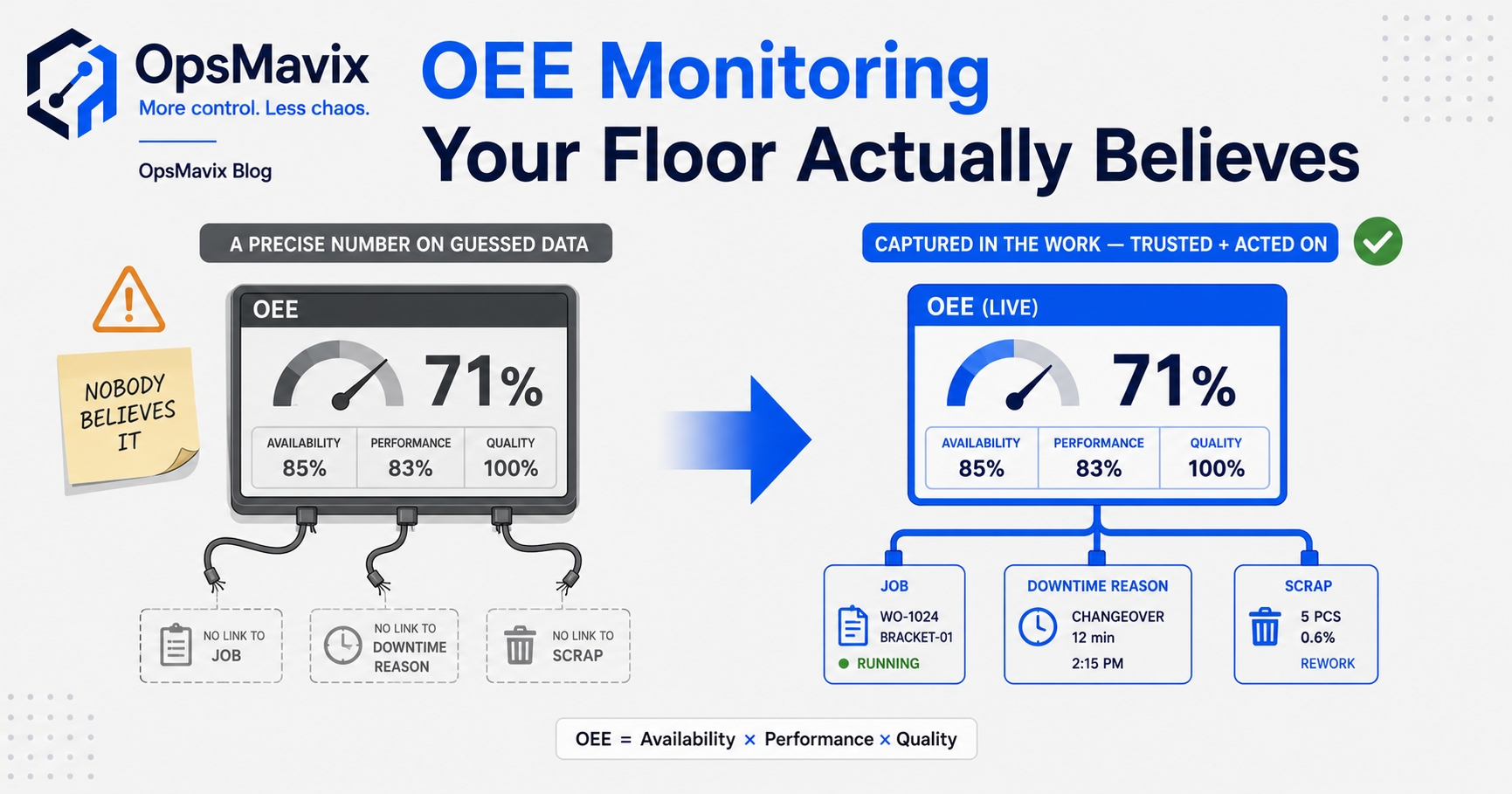
OEE monitoring is only worth doing if the number it produces is one your floor actually believes. OEE — Overall Equipment Effectiveness, the product of Availability × Performance × Quality — is meant to tell you, in a single figure, how much of your machine’s potential you’re really getting. Useful in theory. The trap in practice is that a wrong OEE number isn’t neutral; it’s worse than having none, because people schedule, invest, and chase improvements based on it. If the downtime under it was guessed, the cycle time was assumed, and the scrap was rounded, you’ve built a confident dial on a foundation of fiction. So the honest answer to “should we monitor OEE” is: yes, but only after you’ve sorted out where the data comes from and who owns the reasons behind it. The dashboard is the easy part. The trustworthy data underneath is the whole job.
This post covers what OEE actually measures, why an expensive standalone OEE platform so often becomes another screen nobody looks at, and how a right-sized system can capture OEE inside the workflow your team already runs — tied to real jobs, real downtime reasons, and real scrap — so the figure is accurate and someone acts on it.
Key Takeaways
- OEE = Availability × Performance × Quality. A single percentage meant to show how much of a machine’s true potential you’re capturing.
- A number nobody trusts is worse than no number. People make decisions on OEE; if the data under it is guessed, the decisions inherit the guess.
- The expensive trap is buying a standalone OEE/machine-monitoring platform that becomes another disconnected dashboard — accurate sensor data, no link to the job, the reason, or the scrap.
- OEE is only as good as its downtime reasons, and downtime reasons only get captured if someone owns them and the logging happens inside the work, not as a separate chore.
- The “world-class 85%” figure you’ll see quoted is an industry rule of thumb, not a target to chase blindly. Your trend on your own honest baseline matters far more than someone else’s number.
- A right-sized custom system captures OEE where work already happens — at the job, the machine, the count — so the figure is trusted and acted on instead of admired and ignored.
1What OEE Monitoring Actually Measures
OEE rolls three losses into one number. Availability asks how much of your planned run time the machine was actually running, not stopped — changeovers, breakdowns, waiting for material. Performance asks whether it ran at its proper speed when it was running, or limped along with minor stops and slow cycles. Quality asks how much of what it made was good first time, not scrap or rework. Multiply the three and you get OEE: a percentage that, done honestly, says “of everything this machine could have produced in the time we gave it, this is the share we actually got.”
That’s the appeal — one figure, three real loss types, a clear sense of where the potential is leaking. The problem is that each of those three inputs has to come from somewhere, and that somewhere is usually a person on a busy floor estimating after the fact. The maths is trivial. The measurement is where it lives or dies.
2A Number Nobody Trusts Is Worse Than No Number
This is the part the OEE vendors skip. If you have no OEE figure, everyone knows they’re working off feel, and they treat it with appropriate caution. The moment you publish a number — 62%, 71%, whatever it is — it stops being feel and starts being fact. People plan capacity off it. Someone tells the bank the line is running at X. A manager decides which machine to invest in because its OEE looks worse. And if that number was built on guessed downtime and assumed cycle times, every one of those decisions inherits the guess, now wearing a suit.
The floor knows when a number is fiction before the office does. The operators who actually ran the machine see “94% availability” on the board, know they were down for an hour waiting on the forklift, and quietly write the whole system off. Once they stop trusting it, they stop feeding it — and now your OEE is both wrong and starved. A bad number doesn’t just mislead; it actively trains your best people to ignore measurement altogether.
3The Standalone-Platform Trap
The obvious move is to buy an OEE or machine-monitoring platform. Bolt sensors to the machines, stream the data, get a glossy dashboard. The pitch is seductive and the technology is genuinely real — automatic uptime/downtime capture is far better than a clipboard. But here’s where it quietly fails for most small and mid-sized shops: the platform knows the machine stopped. It does not know why, it does not know which job was running, and it usually does not know whether the parts that came off were good.
So you end up with a precise record of red and green time, sitting in its own portal, disconnected from your scheduling, your job tracking, and your quality data. Someone has to manually reconcile “the machine was down 09:14–10:02” with “that was the changeover for the Henderson order, and we scrapped six on first-off.” That reconciliation never happens consistently, so the dashboard drifts into the same graveyard as every other tool that didn’t fit the way the shop runs. Manufacturers describe this pattern with weary recognition — paying real money and still being left with manual work: “Be prepared to still have manual input… despite paying high dollars.” An OEE platform that doesn’t connect to the job and the reason is just a very expensive stopwatch.
4Downtime Reasons Are the Whole Game — and Someone Has to Own Them
The single most valuable part of OEE monitoring isn’t the percentage. It’s the breakdown of why the machine wasn’t producing — and that breakdown only exists if downtime reasons get captured, accurately, every time. “Machine down 47 minutes” tells you nothing actionable. “Machine down 47 minutes: 30 waiting for material, 12 changeover, 5 tooling” tells you exactly where to spend your next improvement hour.
Two things have to be true for that to work. First, the reasons have to be logged inside the work, in the moment — a quick tap on the screen the operator is already using, not a paper form filled in from memory at end of shift. Logged late, it’s invented. Second, someone has to own the reason codes: keep the list short and real, kill the catch-all “other” that swallows half your downtime, and actually look at the breakdown weekly. Without an owner, the categories rot, “other” balloons, and the data goes soft. This is the unglamorous, human half of OEE that no platform sells you, because you can’t buy it — you have to build the habit, and the system has to make the habit nearly effortless.
5Tie OEE to the Job, the Scrap, and the Schedule
OEE in isolation is a number. OEE connected to the rest of your floor is a tool. When the same system that tracks your jobs also captures run time, downtime reasons, and scrap, the figure stops being abstract: you can see that the Henderson job ran at 58% OEE because of two long material waits, that a particular product family always scraps on first-off, that one machine’s “performance” loss is really a tooling problem nobody flagged because it never had a home.
That connection is exactly what a standalone platform can’t give you and what most off-the-shelf MRP treats as an afterthought. It also flips OEE from a retrospective scorecard into something that touches scheduling — if you know a machine’s real, honest availability, you can plan against reality instead of against the optimistic number on the spec sheet. This is the same logic behind treating production as one connected flow rather than a stack of disconnected tools; see what an operations system actually is and how it shows up in day-to-day shop-floor job tracking.
6The “World-Class 85%” and Other Numbers to Distrust
You will be quoted 85% as “world-class OEE” by roughly every vendor and consultant. Treat it as a rough industry rule of thumb, not a target to chase or a stick to beat your floor with. It’s a qualitative reference point that bundles assumptions about your process, product mix, and what you even count as planned time. A high-mix shop doing short runs with frequent changeovers will have a structurally different ceiling than a line running one product for a week. Comparing your honest 61% to someone else’s claimed 85% mostly tells you their definitions are looser than yours.
The number that matters is your own trend on a baseline you trust. Measure honestly, leave the definitions fixed, and watch whether the line moves. A real 61% that’s climbing because you fixed the material-wait problem is worth infinitely more than an impressive 84% built on generous assumptions and quiet rounding. Chase the trend on honest data, not someone else’s headline figure.
7Right-Sizing OEE Monitoring So It Actually Gets Used
The point of OEE isn’t a beautiful dashboard; it’s a number the floor trusts enough to act on. That means right-sizing it to your shop. You almost certainly don’t need a six-figure machine-monitoring deployment across every asset on day one. You need honest capture on the machines that constrain you, reason codes that match how your people actually talk about downtime, and the figure surfacing where work already happens — at the job screen the operator uses, not in a separate portal they have to remember to open.
This is the gap most manufacturers fall into: too messy for a spreadsheet that someone updates from memory, but nowhere near ready for a heavyweight platform that demands you bend the shop to its one way of working. A right-sized system meets the shop where it is. It captures OEE as a by-product of running the job properly, not as an extra reporting chore, so the data stays honest because logging it is the path of least resistance. Built around your real floor, it lives in the same place as your production tracker and your factory management software — or a right-sized manufacturing execution system — instead of beside them, ignored.
Off-the-Shelf OEE Tool vs a Built-For-You System
| Off-the-Shelf OEE / Machine-Monitoring Platform | Built-For-You System | |
|---|---|---|
| What it captures | Machine up/down time, often via sensors | Run time, downtime reasons, scrap — tied to the job |
| Knows the “why” | Rarely — logs the stop, not the cause | Yes — reason codes captured inside the work |
| Linked to your jobs | Separate portal; manual reconciliation | One flow — OEE sits next to the job and schedule |
| Linked to scrap/quality | Usually not | Yes — quality loss counted from your real scrap data |
| Reason-code ownership | Generic list; “other” swallows everything | Short, real codes shaped to how your floor talks |
| Floor adoption | Another dashboard to remember to open | Surfaces where operators already work |
| Cost shape | Per-machine licences / per-seat, ongoing | Fixed-scope build, owned outright |
| Fit to your shop | Bend the shop to the tool’s one way | Built around your real floor and product mix |
| What you end up with | Precise red/green time nobody acts on | A number the floor trusts and uses |
Common Questions
What is a good OEE score for a small manufacturer?
The honest answer is: a good score is an honestly measured one that’s trending up. The “85% world-class” figure gets quoted everywhere, but it’s a rough industry rule of thumb that bundles a lot of assumptions, and a high-mix shop with frequent changeovers has a different realistic ceiling than a long-run line. Don’t chase someone else’s number. Fix your definitions, measure honestly, and watch whether your own baseline improves. A real 60% that’s climbing beats a flattering 84% built on rounding.
Do I need machine sensors to monitor OEE?
Not necessarily, and not on every machine. Sensors give you accurate uptime/downtime capture, which is genuinely better than a clipboard, but they only tell you the machine stopped — not why, not which job, not whether the parts were good. For many small and mid-sized shops, the bigger win is capturing reasons, jobs and scrap together inside the work, with sensors added only on the machines that actually constrain you. The data connection matters more than the data source.
Why does my OEE dashboard get ignored?
Almost always one of two reasons. Either the number isn’t trusted — the floor knows the downtime was guessed, so they write the whole thing off — or the dashboard lives in its own portal, disconnected from the jobs and scrap, so nobody can answer “why is it low?” without manual digging. Fix both: capture the data inside the work so it’s honest, and put OEE where people already are so acting on it costs no extra effort.
Can I add OEE monitoring to the system I already use?
Often yes, and that’s usually the right move. The goal isn’t a separate OEE product; it’s OEE captured as part of how you already track jobs and production, so the figure is connected to the reasons and the scrap behind it. Built into your existing flow, OEE becomes a by-product of running the job properly rather than a separate reporting task that quietly stops getting done.
How OpsMavix Can Help
OpsMavix builds the part of OEE monitoring that makes it worth doing: trustworthy data, captured inside the work your floor already does. Instead of bolting on another standalone dashboard, we build OEE into your production tracking — run time, downtime reasons, and scrap tied to the actual job and the actual machine — so the number means something and someone can act on it. Reason codes are shaped to how your people genuinely describe downtime, logging happens in the moment with a tap rather than a memory, and the figure surfaces where operators already work instead of in a portal they have to remember to open. You own the system outright — no per-machine licences, no per-seat fees, nothing a vendor can switch off or price-hike out from under you.
If your OEE is either guessed, ignored, or sitting in a dashboard nobody trusts, the honest first step is finding out where the data actually breaks. Book an Operations Leak Audit and we’ll map where your downtime, scrap and run-time numbers go soft, what the blind spots are costing you, and whether right-sized OEE monitoring belongs inside the system you already run.